오늘은 SQL SERVER의 인덱스 탐색방법에 대해 포스팅 하고자 합니다.
INDEX SCAN
인덱스의 리프 페이지를 모두 스캔하는 방식으로 수행됩니다. 흔히 말하는 풀스캔으로 이해하시면 좋을 것 같습니다.
실행계획에 표기된 INDEX SCAN 동작 방식이 무조건 성능 저하를 발생시키는 요인으로 알려져 있지만,
아래 케이스와 같이 예외적인 케이스가 있다는 것도 참고 하시길 바랍니다.
INDEX SEEK (인덱스 탐색)
인덱스 탐색은 필요한 리프페이지만 탐색하여 접근합니다.
탐색 순서는 루트 -> 브랜치 -> 리프 페이지이며, 자세한 설명은 인덱스 페이지 구조 및 확인 방법에서 다시 포스팅할 예정입니다. 일반적인 OLTP 환경에서 적합한 방식이며, 옵티마이저 (성능 최적화 프로그램)이 INDEX SEEK 탐색을 할 수 있도록 인덱스 설계 및 쿼리의 조건 변경을 통해 성능 개선이 가능합니다.
INDEX SCAN VS INDEX SEEK
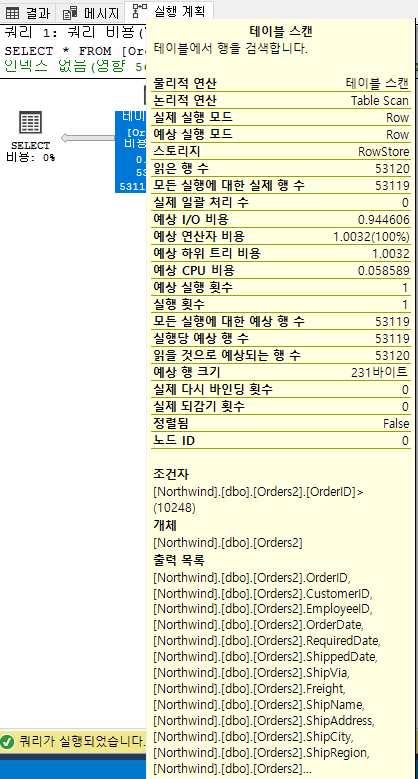
orders2 테이블은 53,120개 행을 가지고 있으며, OrderId를 넌클러스터 인덱스를 가진 테이블입니다.
아래의 경우 OrderID라는 인덱스 키로 조회하지만, 옵티마이저가 인덱스 SEEK 가 아닌 SCAN 방식을 선택하였습니다.

select * from Orders2 where OrderID > 10248

임의로 인덱스 힌트를 추가하여 인덱스 SEEK를 타도록 변경하였습니다.
select *
from Orders2 with(index =ix_orders2_OrderID)
where OrderID > 10248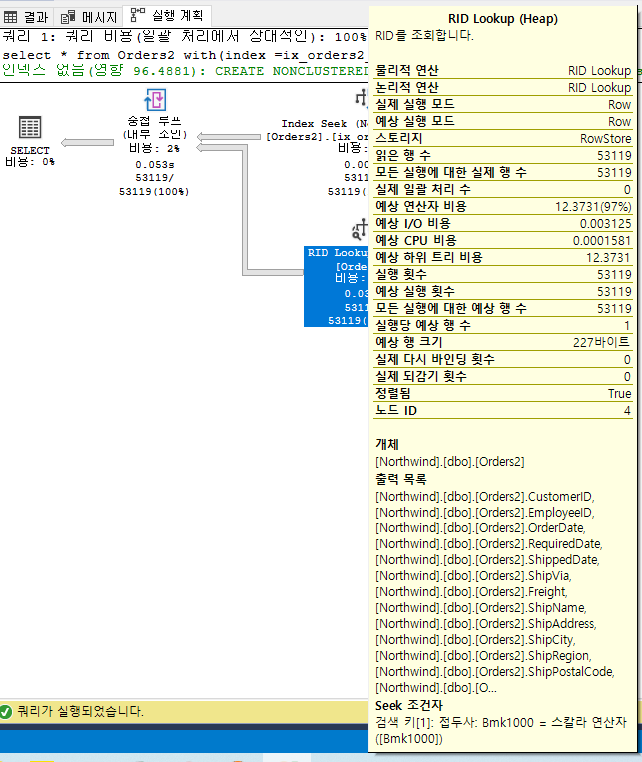

당연한 결과지만, 넓은 범위에 데이터를 조회하는 경우 넌클러스터 인덱스의 경우 RID 조인을 위해 랜덤 I/O가 발생하므로, I/O 비용이 40배이상 증가한 것으로 확인할 수 있습니다.
위와 같은 케이스를 통해 옵티마이저가 INDEX SCAN 처리하는 경우가 INDEX SEEK에 대해 잘판단하여 작동했다고 볼수 있습니다.
넓은 범위의 데이터를 넌클러스터인덱스 키를 활용하여 조회하는 경우 참고하면 좋을 것 같습니다.
'SQL SERVER' 카테고리의 다른 글
| SQL SERVER clustered index , nonclustered index (0) | 2022.04.27 |
|---|---|
| SQL SERVER 비용이 높은 쿼리 보기 (fT. dm_exec_query_stats) (0) | 2022.02.20 |
| SQL SERVER 프로파일 쿼리로 실행하기 (0) | 2022.02.16 |
| SQL SERVER 데드락(lock) 조회하기 (0) | 2022.02.14 |
| 인덱스 페이지 확인하는 방법 (FT. DBCC IND, DBCC PAGE) (0) | 2022.02.13 |




댓글